Understanding Transformers: The Backbone of Modern AI

I'm the founder of CareerPod, a Software Quality Engineer at Red Hat, Python Developer, Cloud & DevOps Enthusiast, AI/ML Advocate, and Tech Enthusiast. I enjoy building projects, sharing valuable tips for new programmers, and connecting with the tech community. Check out my blog at Tech Journal.
Introduction :

Hey everyone 👋🏻 !
Let me Introduce Transformers wait a minute, not the movie! Though, I have to admit, the Transformers movies are pretty cool, especially the Autobots and Megatrons . But today, I’m here to introduce something even cooler the Transformer model, which has completely changed the AI industry.
The Transformer model and its architecture were proposed by a group of Google researchers in the 2017 paper Attention Is All You Need. This innovation revolutionized the entire AI landscape. These models power state-of-the-art Natural Language Processing (NLP) applications, including GPT, BERT, and T5. Unlike traditional models like RNNs and LSTMs, Transformers leverage the self-attention mechanism to process data more efficiently, leading to groundbreaking advancements in machine learning and artificial intelligence.
In this blog, I will break down Transformers, Transformer architecture, its components (encoders, decoders, attention mechanisms), and its impact on AI. I will also provide a hands-on example using the Gensim library. No need to worry—it won’t be too mathematical!
Understanding Some Fundamentals
Before diving into Transformers, let’s first understand some key concepts.
What is a Language Model?
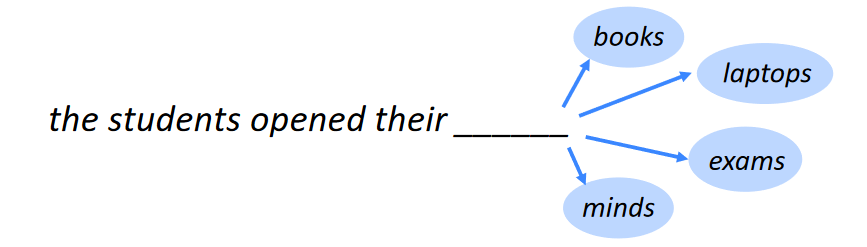
A language model is essentially a system that predicts the next word in a sentence. For example:
Google's popular language model is BERT.
OpenAI's ChatGPT is based on the GPT model.
GPT is called a large language model (LLM) because it is trained on billions of parameters, making it incredibly powerful. The primary goal of a language model is to predict the next word in a sentence accurately.
Word Embeddings and Tokens
Machine learning models don't understand text directly; instead, they work with numerical representations known as word embeddings. Before feeding text into a Transformer model, words are broken down into tokens and transformed into embeddings.
For example:
- The phrase "river bank" and "financial bank" will have different embeddings, even though they share the word bank.
Tokens

Tokens are the smallest units of text used in Natural Language Processing (NLP). The process of breaking text into these smaller units is called tokenization.
Example:
- "unbelievable" → ["un", "believable"]
Why Have Transformers Revolutionized AI?
Transformers have redefined AI due to several key factors:
Parallel Processing – Unlike RNNs, which process words sequentially, Transformers analyze the entire input at once, making them significantly faster.
Better Context Understanding – Transformers capture long-range dependencies, allowing them to understand language better than traditional models.
Scalability – Models like GPT-4 and BERT demonstrate how well Transformers scale with massive datasets.
Versatility – Used in chatbots, translation, summarization, text generation, image processing, and more.
Transformer Architecture: A High-Level Overview
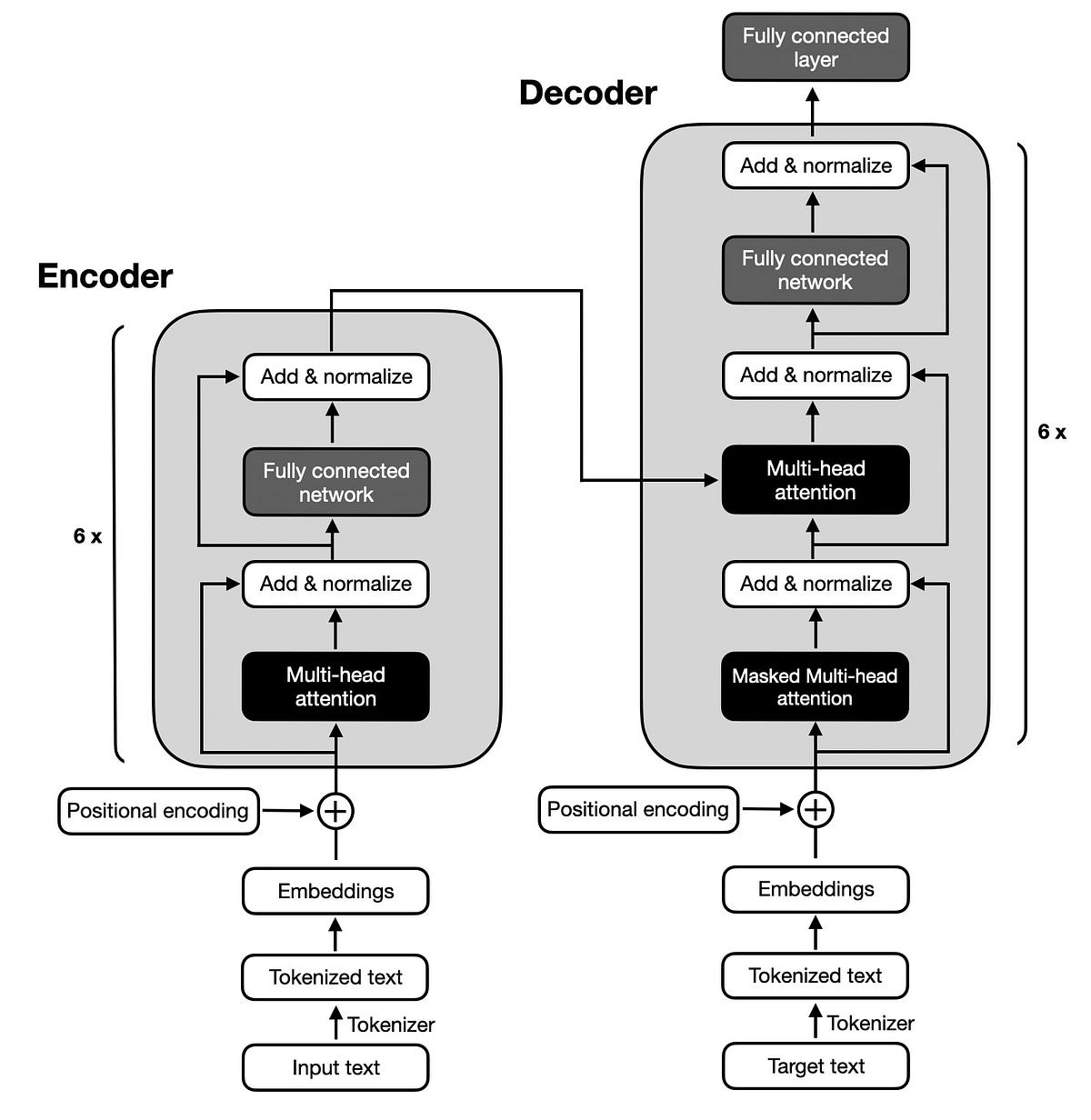
Transformers follow an encoder-decoder architecture. Here’s a simplified breakdown:
Encoder: Takes the input sentence, generates embeddings for each word/token, and produces contextual embeddings.
Decoder: Uses the contextual embeddings to predict the next word, generating an output with the highest probability.
Variants of Transformers
Transformer: Generic encoder-decoder architecture.
BERT: Only has an encoder.
GPT: Only has a decoder.
Understanding Encoders and Decoders
Encoder:
Converts input tokens into meaningful representations.
Uses self-attention to understand relationships between words.
Stacks multiple layers for deep feature extraction.
Decoder:
Takes encoder outputs and generates predictions.
Uses self-attention + cross-attention to ensure coherence in output.
Static vs. Contextual Embeddings
Static Embeddings: Pre-trained word representations like Word2Vec, GloVe.
Contextual Embeddings: Transformer-generated dynamic embeddings that change based on context.
Example:
- "bank" in "river bank" vs. "financial bank" will have different embeddings in Transformer models.
Attention Mechanism: The Heart of Transformers
Self-Attention:
Each word attends to every other word in a sentence.
Helps the model understand context efficiently.
Multi-Head Attention:
Instead of using a single attention mechanism, Transformers use multiple parallel attention heads.
Each head captures different aspects of meaning.
Cross-Attention:
- Used in the decoder to attend to encoder outputs, ensuring context-rich responses.
How Text is Converted into Output (Step-by-Step)
Tokenization: Text is broken into smaller units.
Embedding: Tokens are converted into numerical vectors.
Positional Encoding: Adds information about word order.
Self-Attention & Multi-Head Attention: Captures contextual relationships.
Feed-Forward Network: Processes extracted features.
Output Generation: Decoder produces meaningful text.
Hands-on Example: Using Gensim for Word Embeddings
Before diving into Transformer-based models, let’s see how word embeddings work with Gensim.
Step 1: Install Gensim
pip install gensim
Step 2: Train a Word2Vec Model
from gensim.models import Word2Vec
# Sample dataset
sentences = [['machine', 'learning', 'is', 'fun'], ['deep', 'learning', 'is', 'powerful']]
# Train Word2Vec model
model = Word2Vec(sentences, vector_size=50, window=3, min_count=1, workers=4)
# Get similar words
print(model.wv.most_similar('learning'))
Conclusion :
Transformers have revolutionized AI, enabling state-of-the-art NLP applications. Their ability to process large datasets, understand context deeply, and handle long-range dependencies makes them the go-to choice for modern AI systems. With further advancements, Transformers will continue to shape the future of AI. 🚀
Connect with me on Linkedin: Raghul M
